by Nick Posegay
Some of the most important tools for medieval Bible translators were translation glossaries. These texts are short lexicographical works, more specialised than complete lexica, that give translations for individual words in a particular Biblical text. Many are extant in Cairo Genizah manuscripts, including Hebrew-Aramaic and Hebrew-Arabic glossaries. Medieval readers could reference these glossaries while studying the Bible, allowing them to quickly identify specific Arabic glosses for uncommon Hebrew words or check which words a particular translator rendered with their Arabic vocabulary. Some of these glossaries correspond to well-known translations produced by professional translators, but others are more personal notes produced by individuals while reading the Bible. Some were probably also used in pedagogical settings to teach young readers. These glossaries are valuable evidence for analysing how medieval Jewish translators understood the Hebrew of their source texts.
The individual personal usage of translation glossaries sometimes preserves dialectal details that are not normally present in standard written Arabic. One glossary in which this occurs is the manuscript fragment known as T-S Ar.5.58, held at the Cambridge University Library.[1] This fragment comes from the Cairo Genizah, a repository of tens of thousands of medieval manuscripts that the Jewish community of Cairo’s Ben Ezra Synagogue stored away when they were no longer fit for use. European scholars procured most of these manuscripts in the late nineteenth century, and the majority now reside in Cambridge.[2]


T-S Ar.5.58 is the only extant folio from what was likely a larger Hebrew-Arabic glossary for the entire book of Samuel. It is made of parchment and written in a trained, though perhaps not professional, Hebrew hand. The text consists of four columns on each face, with the first and third listing Hebrew words from 1 Samuel 17:7-19:10, and the second and fourth providing Judaeo-Arabic glosses. Many of the selected words are relatively uncommon, which it makes sense for a glossary that would have been consulted as a quick reference while reading the Bible. In general, the Hebrew forms conform to the standard Masoretic text, although there are minor variations in the use of matres lectionis. Based on the manuscript’s codicology and palaeography, it is datable to between the tenth and twelfth centuries.
The Judaeo-Arabic translations make this glossary especially useful for Arabic historical linguistics. It is almost completely vocalised with Tiberian Hebrew vowel points, allowing for a much more precise reconstruction of the scribe’s native Arabic dialect than would be possible with Arabic vowel signs. Most medieval Judaeo-Arabic manuscripts are either unvocalised or have only sporadic vocalisation, so fully vocalised Judaeo-Arabic is rare, especially in manuscripts as old as T-S Ar.5.58.[3] We can see the advantages of the Hebrew transcription in this manuscript’s record of several non-standard Arabic features that are also observed in modern dialects.
One well-known feature of spoken Arabic is called imāla (‘bending down, inclination’), which signifies the fronting of a towards i in certain phonetic contexts. This shift is almost always unmarked in regular Arabic writing, but the scribe recorded it in Judaeo-Arabic with the Tiberian vowels ḥiriq (i) and ṣere (e). For instance, several times ṣere marks long ē as an allophone of Arabic ā:
 Fig. 1: وحامل (‘and a bearer’) vocalised wa-ḥēmil.[4]
Fig. 1: وحامل (‘and a bearer’) vocalised wa-ḥēmil.[4]
 Fig. 2: وبالقناة (‘and with the spear’) vocalised wa-bi-al-qanēh.
Fig. 2: وبالقناة (‘and with the spear’) vocalised wa-bi-al-qanēh.
 Fig. 3: الأجانب (‘the foreigners’) vocalised al-agēnib.
Fig. 3: الأجانب (‘the foreigners’) vocalised al-agēnib.
Ṣere also marks imāla of the singular feminine ending (tāʾ marbūṭa):
 Fig. 4: بالمخلة (‘in the bag’) vocalised bil-miḫleh.
Fig. 4: بالمخلة (‘in the bag’) vocalised bil-miḫleh.
In fully vocalised Arabic-script writing, all of these words would be marked with fatḥa, even if speakers pronounced them with e. The Hebrew signs thus allow us to extract vernacular phonology from a written text. Another example comes with the Hebrew vowel point ḥolam (o), which again has no equivalent Arabic sign:
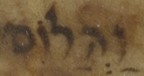 Fig. 5: وهلوم (‘and onwards’) vocalised wa-halōm.
Fig. 5: وهلوم (‘and onwards’) vocalised wa-halōm.
This phrase is analagous to the Classical Arabic هَلُمَّ (‘onwards’), apparently read here with a loss of the final gemination, compensatory lengthening of the ḍamma, and a shift from u to o. Similar lengthening and loss of gemination appears in other words from the glossary,[5] but wa-halōm is the only example with ḥolam.
Another feature that the Tiberian Hebrew pointing system has which does not exist in Arabic is a dot, known as dageš, that marks fricative and stop-plosive allophones of a single Hebrew letter. Arabic letters do not have the same allophonic tendencies, but there are not enough letters in the Hebrew alphabet to represent all Arabic consonants on a one-to-one basis. To compensate, this manuscript’s scribe used dageš consistently to indicate fricative or plosive reflexes of Hebrew consonants that correspond to an Arabic consonant. For example, Hebrew kāf with dageš (כּ) stands for the plosive Arabic kāf (ك), but without dageš (כ) it represents the fricative ḫāʾ (خ):
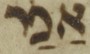 Fig. 6: أخر (‘other’) without dageš in the kāf, vocalised aḫar.
Fig. 6: أخر (‘other’) without dageš in the kāf, vocalised aḫar.
 Fig. 7: المعركة (‘the battlefield’) with dageš in the kāf and vocalised with imāla: al-maʿrakih.
Fig. 7: المعركة (‘the battlefield’) with dageš in the kāf and vocalised with imāla: al-maʿrakih.
This consistent use of dageš allows us to detect another dialectal feature that is familiar from Egyptian Arabic. In Tiberian Hebrew, the letter gimel with dageš (גּ) indicates a velar stop g, while gimel without dageš is a voiced velar fricative ġ. The manuscript’s scribe used gimel and dageš in this way to differentiate Arabic ǧīm (ج) from ġayn (غ),[6] rather than the more common ways of marking Judaeo-Arabic ǧīm with a supralinear or sublinear dot. This practice suggests that the scribe perceived their pronunciation of ǧīm as equivalent to Hebrew gimel with dageš – that is, as g. For instance:
 Fig. 8: جميع (‘everyone’) pointed as gamīʿ.
Fig. 8: جميع (‘everyone’) pointed as gamīʿ.
 Fig. 9: الأجانب (‘the foreigners’) pointed al-agēnib.
Fig. 9: الأجانب (‘the foreigners’) pointed al-agēnib.
 Fig. 10: يوجرّب (‘he tests’) pointed yūgarrib. Also note the use of dageš like shadda to mark the doubled rāʾ.
Fig. 10: يوجرّب (‘he tests’) pointed yūgarrib. Also note the use of dageš like shadda to mark the doubled rāʾ.
 Fig. 11: جوثَت (‘the corpse of’) pointed gūṯat. The scribe wrote the construct form of the word with final tāʾ rather than tāʾ marbūṭa, mimicking Hebrew orthography. Also note the use of dageš to mark the alveolar stop (t) but its absence for the interdental fricative (ṯ).
Fig. 11: جوثَت (‘the corpse of’) pointed gūṯat. The scribe wrote the construct form of the word with final tāʾ rather than tāʾ marbūṭa, mimicking Hebrew orthography. Also note the use of dageš to mark the alveolar stop (t) but its absence for the interdental fricative (ṯ).
By contrast, gimel without dageš consistently indicates ġ in the manuscript. For example:
 Fig. 12: ليغنّي (‘in order to sing’) pointed as li-yuġannī, without dageš in the gimel, but with dageš marking gemination of the nūn.
Fig. 12: ليغنّي (‘in order to sing’) pointed as li-yuġannī, without dageš in the gimel, but with dageš marking gemination of the nūn.
This notation corresponds with the common pronunciation of ǧīm (or rather, gīm) in both medieval and modern Egyptian dialects.[7] Such a detail would undetectable if the glossary were written in Arabic characters, as the scribe would have used ج to represent g. It seems that, at least for this writer, the Tiberian Hebrew system was more effective than the Classical Arabic system for transcribing the colloquial pronunciation that they used when reading the Bible in Arabic.
Besides the allophonic vocalisation and the gīm reflex, this glossary contains a number of other non-standard forms that diverge from Classical Arabic. For instance, the standard Arabic حُرّ (‘a noble’) is transcribed ḥūr:
 Fig. 13.
Fig. 13.
The second masculine singular object and possessive suffixes are transcribed as -ak, the same as modern Egyptian and Levantine Arabic dialects:
 Fig. 14: قحتك (‘your insolence’) pointed as qiḥatak.
Fig. 14: قحتك (‘your insolence’) pointed as qiḥatak.
 Fig. 15: يوسلّمك (‘he will deliver you’) pointed as yūsallimak.
Fig. 15: يوسلّمك (‘he will deliver you’) pointed as yūsallimak.
It also seems that the scribe sometimes heard an epenthetic short vowel in positions where we would expect kāf to close a syllable:
 Fig. 16: تركت (‘you left’) pointed as tarakat.
Fig. 16: تركت (‘you left’) pointed as tarakat.
 Fig. 17: يكملو (‘they become complete’) pointed as yakimalū.
Fig. 17: يكملو (‘they become complete’) pointed as yakimalū.
These examples are only a few of the variations that remain preserved due to the scribe’s careful work in vocalising the finest details of their Arabic reading tradition.
T-S Ar.5.58 is a fragment of a medieval Judaeo-Arabic translation glossary for the book of Samuel. From an exegetical standpoint, it shows us how a particular Egyptian Jew interpreted Samuel via the Arabic words that they chose to translate its Hebrew vocabulary. In terms of linguistics, it is especially valuable for its precise record of its scribe’s pronunciation of Arabic. We have seen that when this person read or recited the Bible in Arabic, in many ways it was more similar to their own native Egyptian dialect than to Classical Arabic. They considered that dialectal register important enough to record with Tiberian Hebrew signs. This written form may be described as a type of ‘Middle Arabic,’ exhibiting a mixture of dialectal and Classical features in a single text and reflecting the unique context of its scribe as a Bible translator in the medieval Arabic world.
Article reference: Nick Posegay, “A Judaeo-Arabic Biblical Glossary as a Source for Arabic Historical Dialectology,” Journal of Arabic and Islamic Studies, no. 20 (2020): 33–52, https://doi.org/10.5617/jais.7863.
Nick Posegay recently completed his PhD in Middle Eastern Studies at the University of Cambridge. He is currently a research assistant at the Taylor-Schechter Genizah Research Unit and will take up a Leverhulme Early Career Fellowship in Cambridge this autumn. His research examines interfaith contact in the intellectual history of Middle Eastern languages, especially focusing on Syriac, Arabic, and Hebrew vocalisation. He has also published on Judaeo-Arabic manuscripts, Syriac scribal culture, and Qurʾan fragments in Genizah collections.
Footnotes
[1] MS Cambridge University Library, Taylor-Schechter Arabic 5.58. My thanks to the Syndics of the University Library and the Taylor-Schechter Genizah Research Unit for allowing me to reproduce images of this fragment. For a full analysis and edition of the manuscript, see Nick Posegay, “A Judaeo-Arabic Biblical Glossary as a Source for Arabic Historical Dialectology,” Journal of Arabic and Islamic Studies, no. 20 (2020): 33–52, https://doi.org/10.5617/jais.7863.
[2] For the history of the Genizah and its discovery, see Stefan C. Reif, A Jewish Archive from Old Cairo: The History of Cambridge University’s Genizah Collection (London; New York: Routledge, 2000); Adina Hoffman and Peter Cole, Sacred Trash: The Lost and Found World of the Cairo Geniza (New York: Nextbook, Schocken, 2011); Rebecca J.W. Jefferson, “Deconstructing ‘the Cairo Genizah’: A Fresh Look at Genizah Manuscript Discoveries in Cairo before 1897,” The Jewish Quarterly Review 108, no. 4 (2018): 422–48.
[3] See Geoffrey Khan, “Vocalized Judaeo-Arabic Manuscripts in the Cairo Genizah,” in “From a Sacred Source”: Genizah Studies in Honour of Professor Stefan C. Reif (Leiden; Boston: Brill, 2010), 201–18; Joshua Blau and Simon Hopkins, “A Vocalized Judaeo-Arabic Letter from the Cairo Genizah,” Jerusalem Studies in Arabic and Islam 6 (1985): 417–76.
[4] The Hebrew šewa sign consistently marks a vowel equivalent to Classical Arabic fatḥa throughout the manuscript. This usage corresponds to the realisation of šewa in the Tiberian pronunciation tradition of Biblical Hebrew. See Geoffrey Khan, The Tiberian Pronunciation Tradition of Biblical Hebrew, vol. I, Cambridge Semitic Languages and Cultures 1 (Cambridge: University of Cambridge & Open Book Publishers, 2020), §I.2.5.2.
[5] Posegay, “A Judaeo-Arabic Biblical Glossary,” 43, n. 53.
[6] On this use of dageš with gimel, see also Nick Posegay and Estara J Arrant, “Three Fragments of a Judaeo-Arabic Translation of Ecclesiastes with Full Tiberian Vocalisation,” Intellectual History of the Islamicate World, 2020, 12–13, https://doi.org/10.1163/2212943X-bja10001.
[7] See Magdalen M. Connolly, “Revisiting the Question of Ğīm from the Perspective of Judaeo-Arabic,” Journal of Semitic Studies 64, no. 1 (April 1, 2019): 155–83, https://doi.org/10.1093/jss/fgy033.
Leave a Reply